文字列の取得やフィールド内容の確認(文字の抽出、大文字・小文字の変換、NULL 値の判定など)を行うための計算式です。
以下はサポートされている関数の一覧です。なお、以下の計算式は大文字・小文字を区別します。
| 関数 | 概要 |
|---|---|
| LEFT(value,length) |
指定した文字数(length)に基づき、文字列の左側から文字を取得します。 例:length が 3 の場合、左から 3 文字を返します。 詳細は こちら をご覧ください。 |
| RIGHT(value,length) |
指定した文字数(length)に基づき、文字列の右側から文字を取得します。 例:length が 3 の場合、右から 3 文字を返します。 詳細は こちら をご覧ください。 |
| MID(value,start,[length]) |
指定した文字列の途中から、指定した文字数を抽出します。開始位置は 0 から数えます。 例:フィールド A1 の値が ABCD の場合、別のフィールドに MID(A1,1,2) を設定すると BC が返されます。 詳細は こちら をご覧ください。 |
| FIND(find_text,within_text,[start_num]) |
文字列内から指定した文字列を検索し、見つかった位置を返します。位置は検索対象文字列の先頭を 0 としてカウントされます。 詳細は こちら をご覧ください。 |
| LEN(value) |
文字列の文字数を返します。 詳細は こちら をご覧ください。 |
| UPPER(value) / TOUPPERCASE(value) |
元の文字列を変更せず、文字列内のすべての小文字を大文字に変換します。 |
| LOWER(value) / TOLOWERCASE(value) |
元の文字列を変更せず、文字列内のすべての大文字を小文字に変換します。 |
| PROPER(value) |
文字列内の各単語の先頭文字、および英字以外の文字に続く英字を大文字にし、それ以外の文字を小文字に変換します。 |
| SUBSTITUTE(text,old_text,new_text,[instance_num]) |
文字列内の特定の文字列(old_text)を、新しい文字列(new_text)に置き換えます。 |
| TEXT() |
数値や日付を、指定した書式に変換します。 詳細は こちら をご覧ください。 |
| REPT(value,number_times) |
指定した値を、指定した回数だけ繰り返して返します。 詳細は こちら をご覧ください。 |
| SPELLNUMBER(number, [lang]) |
数値を英語などの単語表記に変換します。 例:「100」を「one hundred」と表示したい場合に使用します。 詳細は こちら をご覧ください。 |
| TRIM() |
フィールド値の先頭および末尾にある全角・半角スペースを削除します。 また、文字列内に複数の全角・半角スペースがある場合は、最初の 1 つのみを残します。 例:TRIM(" a c ") は "a c" を返します。 |
| CHAR(value) |
指定した文字コードに対応する文字を返します。 例:CHAR(10) は改行、CHAR(32) はスペースを返します。 |
| ISBLANK() |
参照しているフィールドが空かどうかを判定します。 特定のフィールドを直接参照したり、条件式内で使用できます。 例:ISBLANK(A2)、または IF(ISBLANK(A2), 'Y', 'N')。 |
文字列の計算式はシンプルです。たとえば、C1 の値が「山本」、C2 の値が「一郎」の場合、「C1 + C2」の結果は「山本一郎」になります。
2 つの文字列の間にスペースを入れたい場合は、「C1 + ' ' + C2」を使用すると、「山本 一郎」となります。
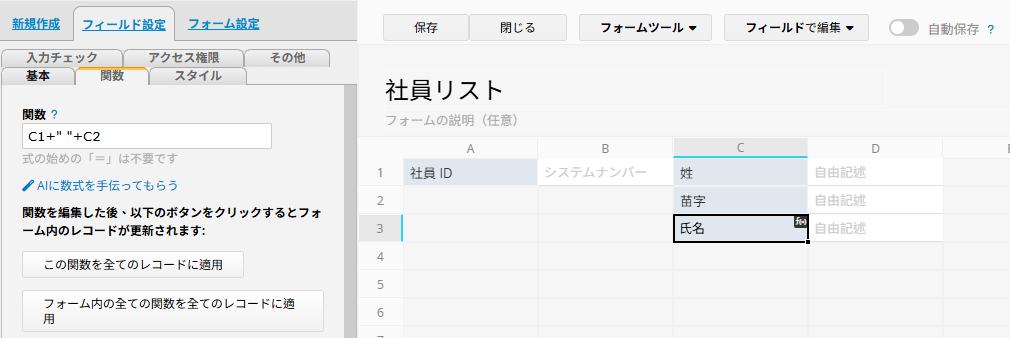
注意: 計算式内で「\」を表現したい場合は、「\\」と記述してください。
LEFT()、MID()、RIGHT()、FIND()、LEN() などの関数を組み合わせることで、テキストフィールドから特定の文字列を柔軟に抽出できます。
| 計算式 | 説明 |
|---|---|
| LEFT(value,length) |
指定した文字数(length)に基づき、文字列の左側から文字を取得します。 例:length が 3 の場合、左から 3 文字を返します。 |
| RIGHT(value,length) |
指定した文字数(length)に基づき、文字列の右側から文字を取得します。 例:length が 3 の場合、右から 3 文字を返します。 |
| MID(value,start,[length]) |
指定した文字列の途中から、指定した文字数を抽出します。開始位置は 0 から数えます。 例:フィールド A1 の値が ABCD の場合、別のフィールドに MID(A1,1,2) を設定すると BC が返されます。 |
| FIND(find_text,within_text,[start_num]) |
他の文字列の中で、指定した文字列が最初に現れる位置を返します(先頭文字を 1 として数えます)。見つからない場合は 0 を返します。find_text は検索する文字列、within_text は検索対象の文字列、[start_num] は検索を開始する文字位置を指定する省略可能な引数です(デフォルトは 1)。たとえば、A1 が "ABCD" の場合、FIND("BC", A1) は 2 を返し、FIND("EF", A1) は 0 を返し、FIND("C", A1, 3) は 3 を返します。 指定した検索文字列(find_text)が空の場合は、1 を返します。詳細は こちらの例をご参照ください。 |
| LEN(value) |
文字列の文字数を返します。 |
例 1: 指定した文字の前後の文字列を抽出する場合
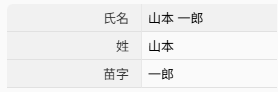
例えば、「氏名」フィールドの値が「山本 一郎」の場合を考えます。

名と姓を別々のフィールドに表示したい場合は、以下の計算式を使用できます。
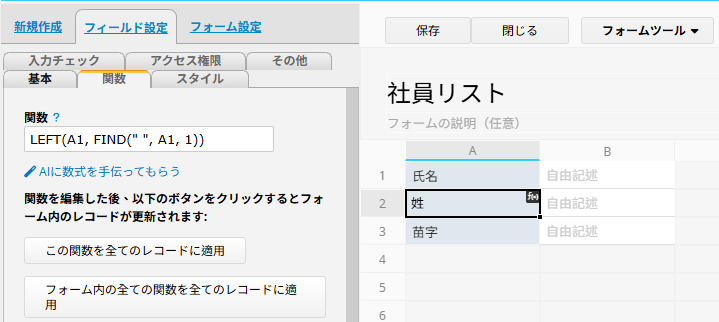
(1) 「姓」を抽出する
「姓」フィールドに、次の計算式を入力します:
LEFT(A1, FIND(" ", A1, 1))
この計算式では、FIND 関数を使って氏名内のスペース(" ")の位置を取得し、その位置までの文字列を LEFT 関数で抽出します。その結果、「山本」が返されます。
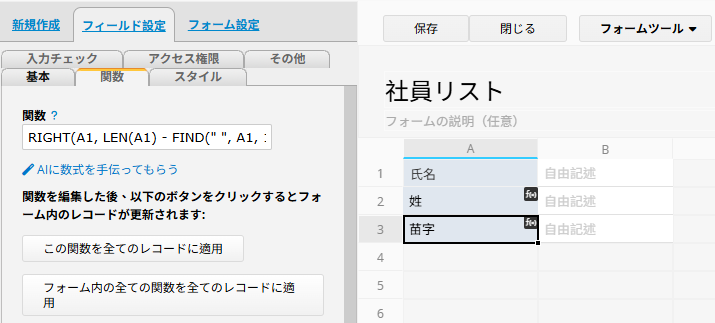
(2) 「苗字」を抽出する
「苗字」フィールドに、次の計算式を入力します:
RIGHT(A1, LEN(A1) - FIND(" ", A1, 1))
この計算式では、LEN 関数で文字列全体の文字数を取得し、スペースの位置を差し引いたうえで、RIGHT 関数を使ってスペースの右側の文字列を抽出します。その結果、「一郎」が返されます。
このようにすることで、「氏名」フィールドの値を自動的に「姓」と「苗字」に分割できます。
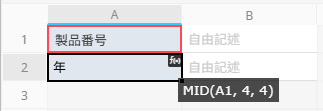
例 2: 文字列の途中から部分文字列を抽出する
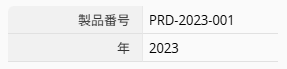
「商品番号」フィールドの値が「PRD-2023-001」で、中央の 4 桁が年を表している場合、「年」フィールドに MID(A1, 4, 4) を入力します。
これにより、5 文字目(インデックスは 0 から開始)から 4 文字が抽出され、「2023」が返されます。
例 3: 検索文字列が空の場合の FIND 関数の返り値と対処方法
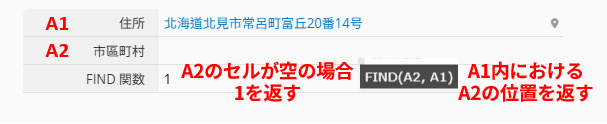
指定した検索文字列(find_text)が空の場合、FIND() は 1 を返します。
たとえば、「市區町村」フィールド(A2)が空の場合、「住所」フィールド(A1)内を検索する FIND(A2, A1) は 1 を返します。
実際の運用では、この結果により「特定のキーワードが含まれているか」を判定する際に誤った解釈につながることがあります。
返り値の 1 が一致として扱われ、その後の計算やフィルターに影響する可能性があるためです。
これを避けるには、ISBLANK() 関数を使って、そのフィールドが空かどうかを先に確認してください。
IF(ISBLANK(A2), "", FIND(A2, A1))
この数式では、まず A2 が空かどうかを確認します。空であれば FIND() は実行せず、空文字列を返します。値が入っている場合のみ、文字列内での位置を返します。

この関数を使用すると、フィールドに特定の書式を適用できます。
| 関数名 | 構文 |
|---|---|
| TEXT | TEXT(value, format_text) |
引数:
value(必須):書式を適用する数値または日付。フィールドを参照できます。
format_text(必須):適用する書式。
数値フィールド
「12,345.67」の形式で表示したい場合は、TEXT(A1, '#,###.##') を使用します。
この計算式は、他の 数値 フィールドの書式にも適用できます。
日付フィールド
曜日を正式名称(例:「Friday」)で表示するには TEXT(A1,'EE') を使用します。
省略形(例:「Fri」)で表示するには TEXT(A1,'E') を使用します。
その他の書式設定については、こちらのドキュメントをご参照ください。
指定した文字列または数値を、指定した回数だけ自動的に繰り返します。
書式調整、配置の整列、記号を使った評価表示などに便利です。
| 関数名 | 構文 |
|---|---|
| REPT | REPT(value, number_times) |
引数:
value(必須):繰り返す文字列または数値。フィールドを参照するか、直接入力できます。
number_times(必須):繰り返し回数。正の整数を指定する必要があります。
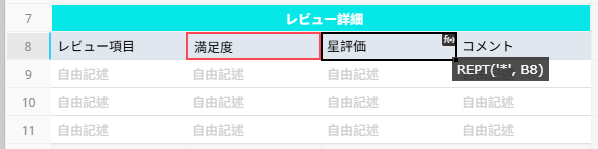
例: 記号を繰り返して満足度を表示する
「星評価」フィールドに REPT("*", "満足度") を入力すると、評価スコアに応じて記号が自動的に繰り返され、視覚的に評価を表示できます。
 貴重なご意見をありがとうございます!
貴重なご意見をありがとうございます!
