
雲端工作術
各類應用示範
案例故事
逃離惡夢
關於 Ragic

不管你是使用 Ragic、其他資料庫系統或其他工具管理資料,可能都會聽到大家在談「Key 值」/「獨特值」(unique value)欄位的重要性。
簡單來說,就是在存放資料時,不管是客戶資料、訂單資料、還是請購單紀錄等等,每一筆資料上面都應該要有一個「專屬於那筆資料、獨一無二的標記」,沒有的話也要新增/配置一個,例如客戶編號、訂單編號、請購單編號。
有了標記,才能讓人依據這個標記來找到、指認這筆資料,就像每筆資料都要有一個門牌號碼,或是每筆資料都要有一個身分證字號一樣。(相關文章可以參考這裡)
等等...說到「身分證字號」,它雖然是一個用來解釋 Key 值的好用概念,實務上也可能有人用它來當會員資料的辨識依據,但你知道台灣有很多人身分證字號是跟別人重複的嗎?
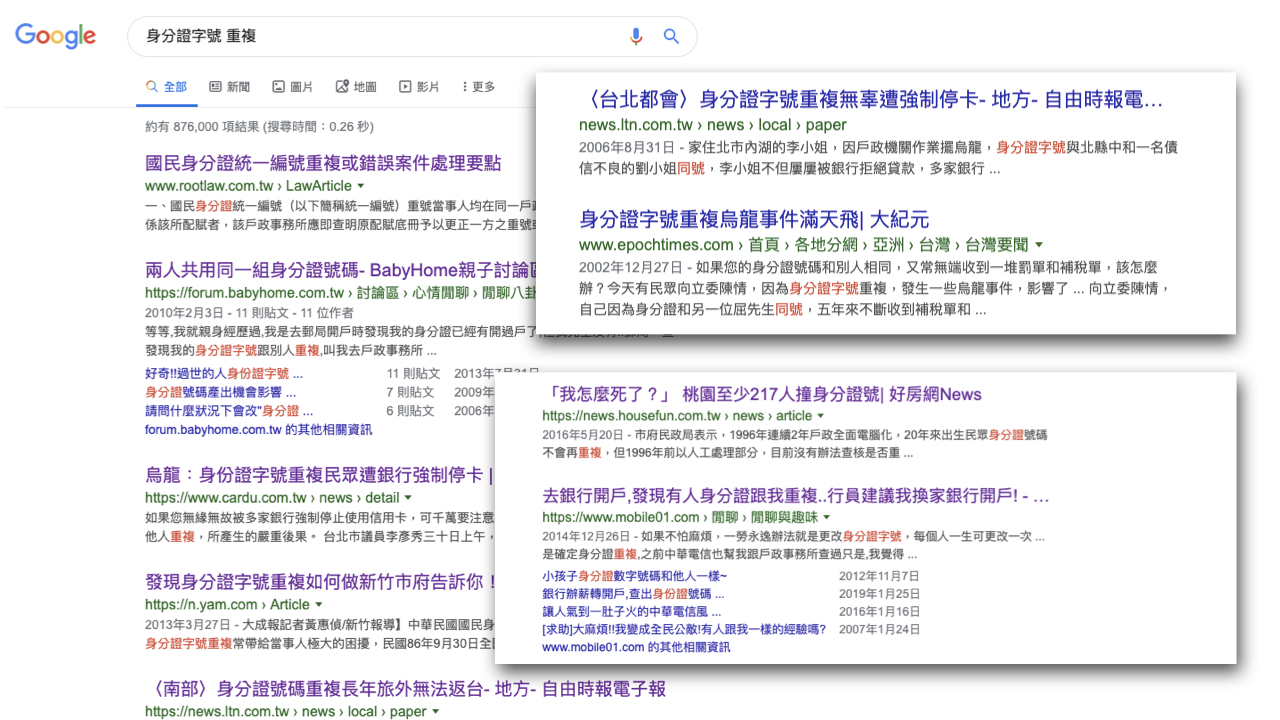
「身分證字號怎麼可能重複?」原本我也是這樣想的,但 Google 輸入「身分證字號 重複」,你會發現網路上已經有一堆案例:無故收到不屬於自己的補稅單、罰單、銀行信用被嚴重影響、辦護照被卡關、補助被取消等等,都因為事主的身分證字號和別人重複,銀行、政府機關「認錯人」導致的。
身分證重號現象的主因,是 1995 年台灣戶政電腦化前,紙本抄錄出錯造成的「歷史共業」。
台灣的身分證統一編號制度民國 54 年就開始實施,起初的幾十年,戶政機關都是以人工抄寫的方式登記戶籍、身份資料甚至製作身分證,只要抄寫員一時筆誤或字跡潦草讓人認錯,就會無意間造成身分證字號重複。
而因為工作流程沒有電腦化,資料都是以紙本形式散放在各地戶政事務所中,沒有大型調查,新竹的戶政事務所不會確知台北有哪些資料,錯誤默默衍生後,要比對全國資料、掌握錯誤並更正也不容易,這些重號的身分證資料就一直存在戶政系統中。
90 年代台灣戶政業務開始逐步電腦化,1995 年各地戶政事務所開始將紙本資料登錄到電腦中、啟動縣市連線作業,各縣市戶政事務所過去散落的資料從此可以連線查看、比對,過去潛伏鮮為人知的「同號問題」馬上浮出水面。
根據 1996 年聯合報的報導,當時光是新竹市第一戶政事務所和其他七個縣市連線後,轄區內就查出千餘件身分證字號「同號」現象。(當時還有戶政人員轉述老一輩說法表示,民國 75 年政府全面換發身分證時,也曾藉著大型更換作業掀開這個「同號問題」,統計出全台有 28 萬件身分證統號重覆,不確定數字是否精確,但跟戶政人員的經驗相符。-- 此段資料來源為 1996/08/27 聯合報07版的報導)
而「身分證同號現象」被發現後,並沒有馬上一一解決,留存至今,2016年桃園市稅務局仍然查出全市有217人稅籍身分證重號。
身分證重號不只是「重號苦主」才要面對的問題,對需要負責客戶資料管理、會員資料管理、員工資料建檔的人來說,這件事代表著不能預設「台灣的身分證字號是獨特值」,因為可能重號,一但你的系統中把身分證字號欄位設成辨識資料的 Key 值欄位,你就會跟那些寄錯稅單、罰單、法院傳票的人一樣,把 A 客戶和 B 客戶搞混。
最近資訊業的話題 -- 南山人壽的新系統「境界計畫」上線亂象,也牽涉到身分證字號重複問題,而天下雜誌的這篇報導中針對這一點特別提到,許多做金融業系統的人都知道要在設定用戶ID時,在身分證字號後加上輔助碼(等於不直接將身分證字號當成辨認用戶的 ID),這是一個避免問題的方法。
最保險的方法是,在設定獨特值欄位時,盡量不要使用外來資料,以自己內部產生的編碼為主,因為外來資料畢竟不是自己可以 100% 掌控的。Ragic 的自動產生欄位值功能就很適合建立這種編碼欄位。

